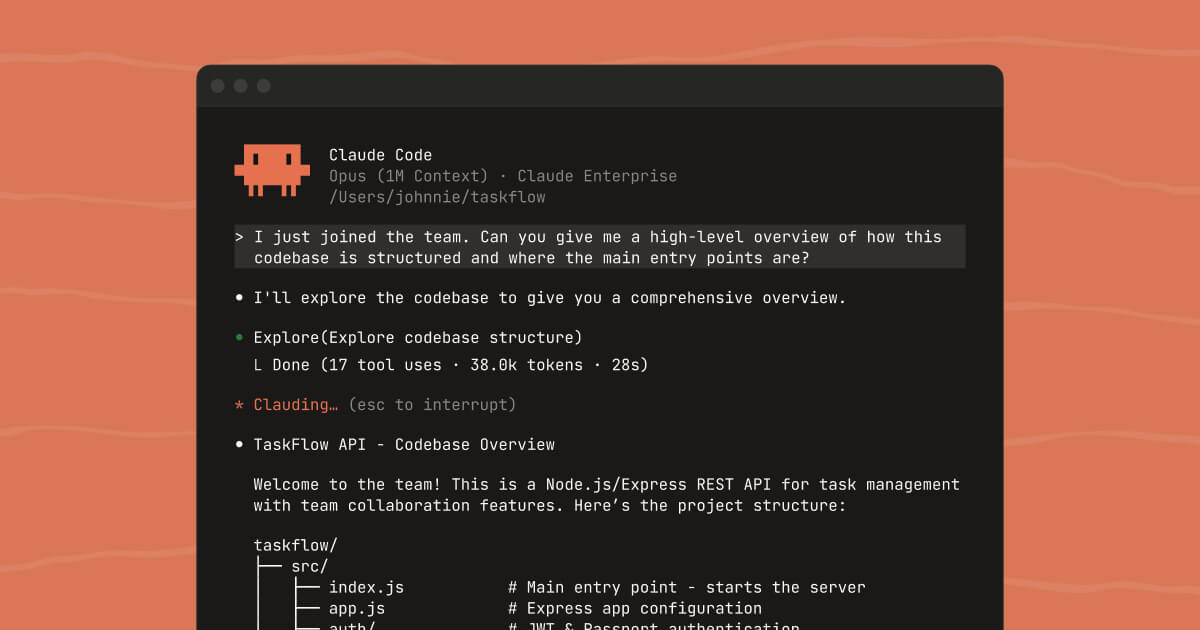
Groq should be viewed as inference infrastructure, not just another chatbot destination. Its positioning centers on giving developers fast model serving and a developer-friendly path to testing and integrating language model workloads that need better latency characteristics.
It fits engineering teams, product developers, agent builders, and technical operators who are deciding whether a model-powered feature can meet user expectations in live systems. The value is strongest when low delay materially changes the user experience or the economics of the product.
What makes Groq worth attention is that speed is not a cosmetic feature in production AI. Faster inference changes conversation feel, workflow fluidity, and how much multi-step logic a team can realistically put in front of users before patience and cost start to break down.
The tradeoff is that fast inference alone does not solve product quality. Model choice, grounding, context management, cost, and safety still determine whether the feature is trustworthy. A quick API is only one part of a usable AI system.
This site recommends Groq for teams evaluating AI infrastructure with clear latency demands. Start with one real API workflow, measure the response profile under realistic prompts, and keep it if the performance improvement materially expands what your product can deliver.